
로딩 중이에요... 🐣
6. Aggregation(집계), Annotation(주석) | ✅ 저자: 이유정(박사)
Aggregation (집계)
여러 행을 계산하여 하나의 결과로 요약하는 것 (예: 평균, 합계, 최대값, 개수 등)
aggregate() 메서드를 사용하고 결과는 딕셔너리로 반환
from django.db.models import Avg
Book.objects.aggregate(avg_price=Avg('price'))
# 결과: {'avg_price': 25000.0}
Annotation (주석/주입된 계산 필드)
각 객체에 계산된 값을 함께 붙여주는 것 (예: 댓글 수, 주문 총액 등)
annotate() 메서드를 사용하고 각 객체에 필드처럼 계산 결과가 추가됨
from django.db.models import Count
Author.objects.annotate(book_count=Count('books'))
# 각 Author 객체에 book_count 속성이 붙음
models.py에서 데이터 스키마(필드들)를 정의해 두면,- 그 위에 Aggregation(집계)이나 Annotation(주석) 메서드를 호출해서
- 모델이 가진 필드를 마치 사칙연산하듯이 더하고(
Sum), 세고(Count), 평균내고(Avg), 최소·최대값을 구하고(Min/Max), 표준편차·분산까지 계산하거나, annotate()로 쿼리셋의 각 객체별로 계산 결과를 속성으로 붙이는
이런 모든 작업을 데이터베이스 레벨에서 한 줄의 ORM 호출로 처리할 수 있습니다.
혹은 더 나아가 Django의 F() 표현식을 섞어서
from django.db.models import F, ExpressionWrapper, FloatField
# 예: price * quantity 계산해서 annotate
Order.objects.annotate(
total_price=ExpressionWrapper(
F('price') * F('quantity'),
output_field=FloatField()
)
)
처럼 필드 간 사칙연산도 가능합니다. 이처럼
- 스키마 정의는
models.py - 그 위에
aggregate/annotate/F()등을 써서 - 실질적인 “계산 로직”을 한 줄로 작성 하면, 복잡한 SQL 없이도 ORM만으로 다양한 통계·계산을 손쉽게 처리할 수 있습니다.
models.py – 아티스트, 앨범, 노래 모델 정의
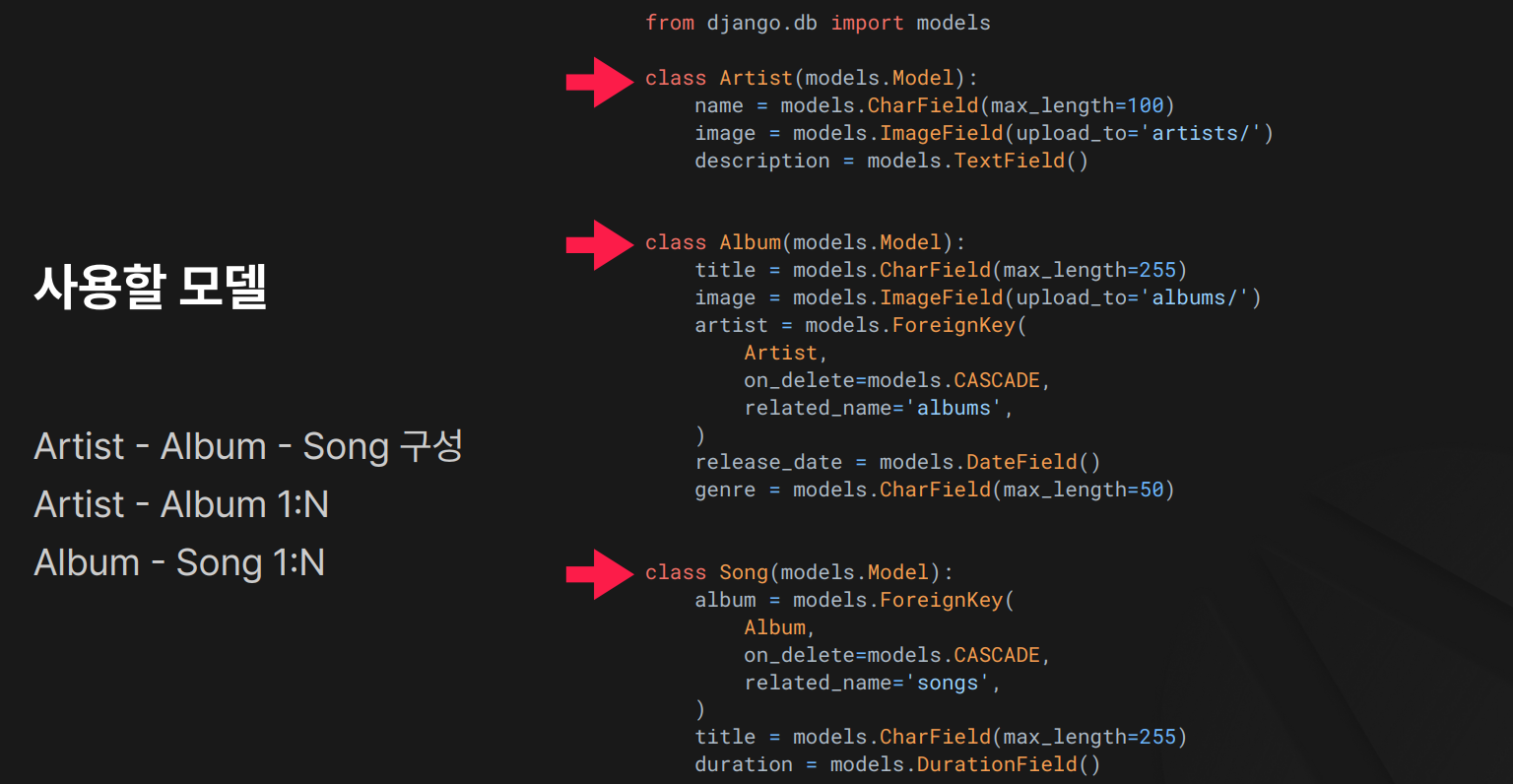 첫 번째 이미지(빨간 화살표)에서 본 대로,
첫 번째 이미지(빨간 화살표)에서 본 대로, Artist ↔ Album ↔ Song 이 1:N 관계로 연결되어 있습니다.
- Artist ↔ Album: 1 : N (
related_name='albums') - Album ↔ Song: 1 : N (
related_name='songs')
aggregate() – 전체 통계 한 번에 계산
앨범 전체에 대한 요약 통계를 QuerySet.aggregate() 로 한 번에 뽑아냅니다.
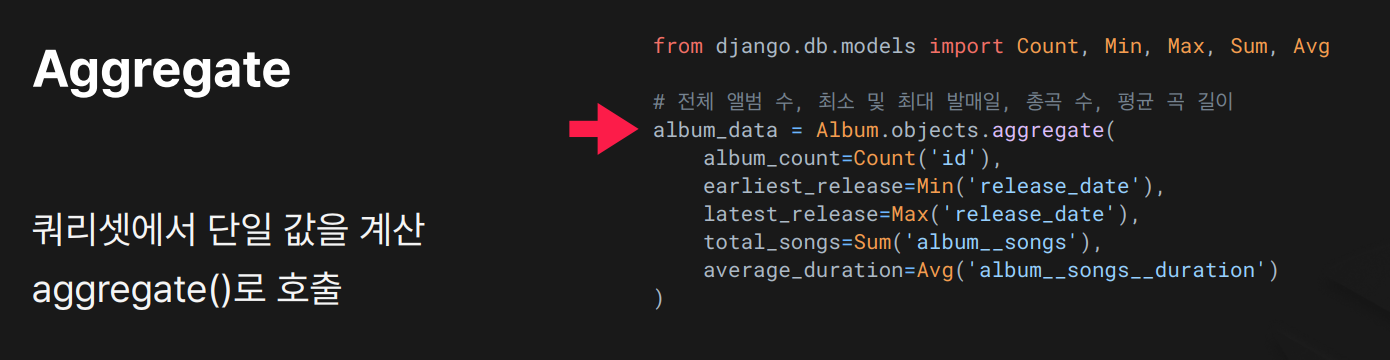 views.py
views.py
from django.db.models import Count, Min, Max, Sum, Avg
album_data = Album.objects.aggregate(
album_count = Count('id'), # 앨범 총 개수
earliest_release = Min('release_date'), # 가장 이른 발매일
latest_release = Max('release_date'), # 가장 늦은 발매일
total_songs = Sum('songs'), # 모든 앨범의 곡 개수 합
average_duration = Avg('songs__duration')# 모든곡의 평균 재생시간
)
- 결과는 하나의
dict Count,Min,Max,Sum,Avg를 이용해 테이블 전체를 요약
분산 통계 추가 (StdDev & Variance)
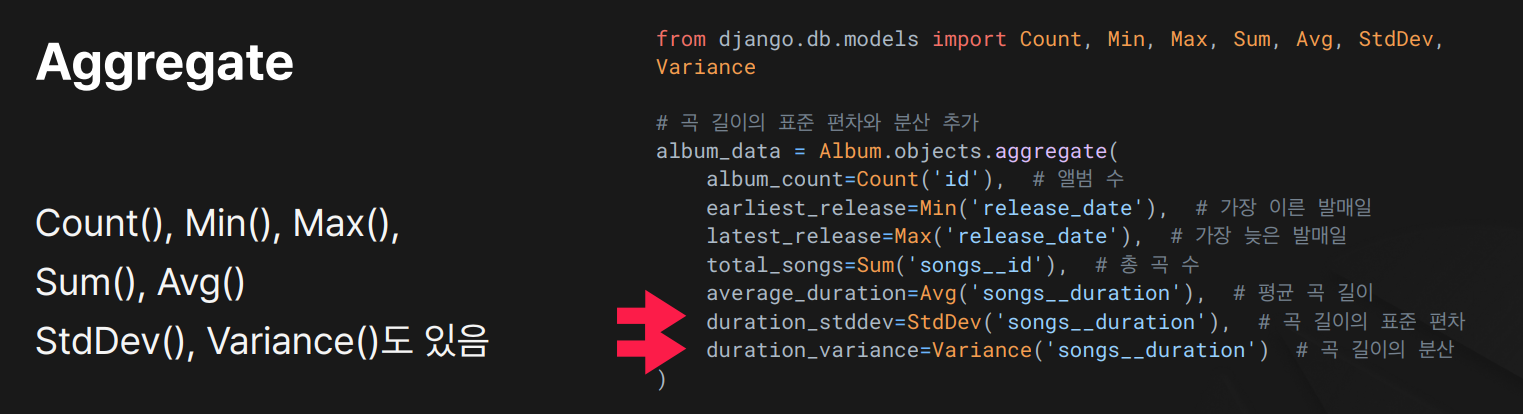 views.py
views.py
from django.db.models import StdDev, Variance
album_data = Album.objects.aggregate(
album_count = Count('id'),
earliest_release = Min('release_date'),
latest_release = Max('release_date'),
total_songs = Sum('songs__id'), # 총 곡 수
average_duration = Avg('songs__duration'), # 평균 곡 길이
duration_stddev = StdDev('songs__duration'),# 곡 길이의 표준편차
duration_variance = Variance('songs__duration')# 곡 길이의 분산
)
- StdDev: 표준편차
- Variance: 분산
default= 인자 사용 예
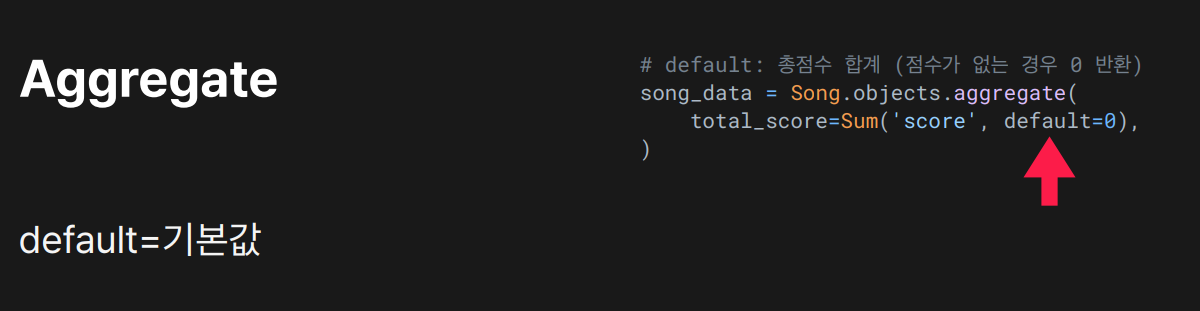 models.py 에 이렇게 정의되어 있습니다.
models.py 에 이렇게 정의되어 있습니다.
class Song(models.Model):
# … 기존 필드들
score = models.IntegerField(default=0)
# …
views.py
song_data = Song.objects.aggregate(
total_score = Sum('score', default=0)
)
score필드가 아예 없는 경우에도 결과가None대신0반환
filter= 파라미터로 조건부 집계
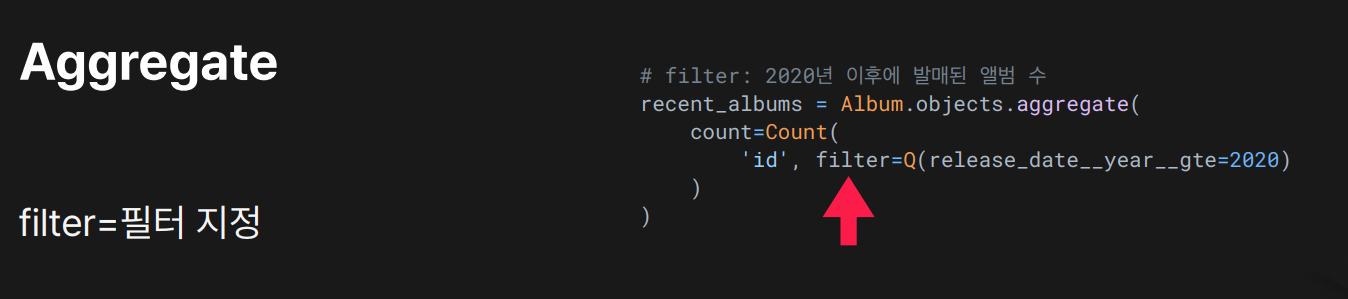
filter=Q(...) 에 지정된 조건(2020년 이후 발매)만 골라서 집계
annotate() — 레코드별 계산 결과 붙이기
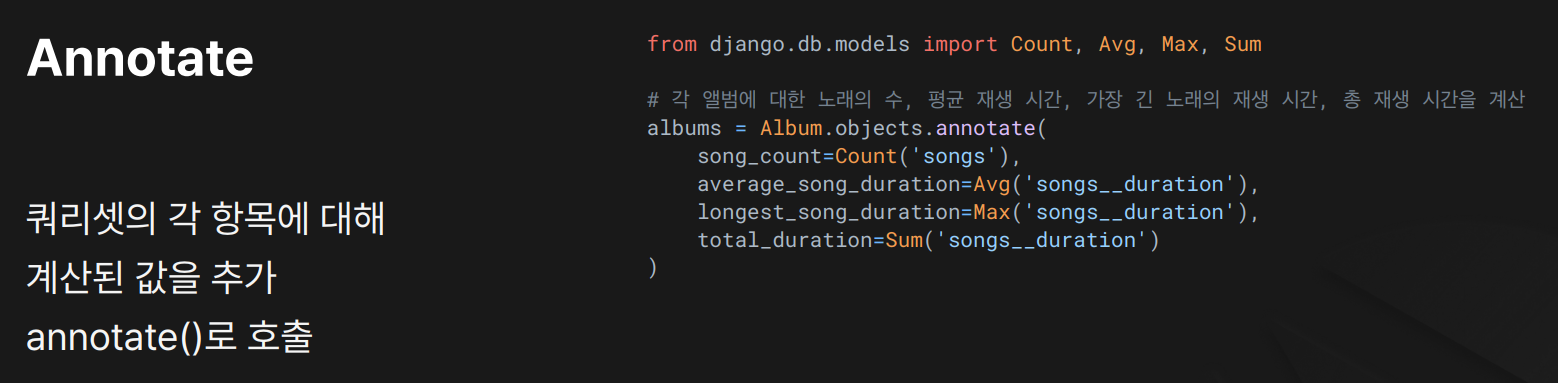
from django.db.models import Count, Avg, Max, Sum
albums = Album.objects.annotate(
song_count = Count('songs'), # 해당 앨범의 곡 개수
average_song_duration = Avg('songs__duration'),
# 해당 앨범 곡 평균 시간
longest_song_duration = Max('songs__duration'),# 최장 곡 시간
total_duration = Sum('songs__duration') # 총재생시간 합계
)
- aggregate() 가 “테이블 전체”에 대한 단일 값 반환이라면,
- annotate() 는 “각 앨범 객체”에 계산된 필드를 추가해서 반환
annotate()를 쓰면 “각 Album 객체”에 대해 계산된 값을 새로운 필드로 붙여준다는 예제입니다.
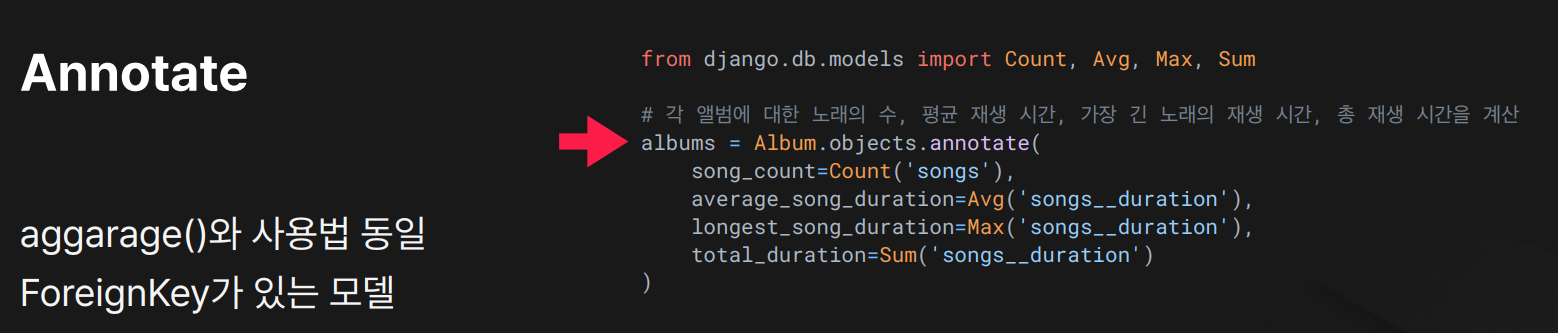
from django.db.models import Count, Avg, Max, Sum
# 각 앨범에 대해:
# - song_count : songs(related_name) 로 연결된 Song 의 개수
# - average_song_duration : songs__duration 필드의 평균
# - longest_song_duration : songs__duration 필드의 최댓값
# - total_duration : songs__duration 필드의 합계
albums = Album.objects.annotate(
song_count = Count('songs'),
average_song_duration = Avg('songs__duration'),
longest_song_duration = Max('songs__duration'),
total_duration = Sum('songs__duration'),
)
annotate()는 내부적으로GROUP BY album.id를 수행해서,- 각 앨범 행(row)에 대해 위에서 지정한 집계 함수를 실행하고,
- 그 결과를
album.song_count,album.average_song_duration등의 속성으로 붙여서 반환합니다.
이렇게 하면:
for alb in albums:
print(
alb.title, # 앨범 제목
alb.song_count, # 곡 개수
alb.average_song_duration, # 평균 곡 길이
alb.longest_song_duration, # 최장 곡 길이
alb.total_duration, # 총 재생 시간
)
반복문 한 번으로 “앨범별 통계”를 바로 꺼내 쓸 수 있습니다.